Bayesian
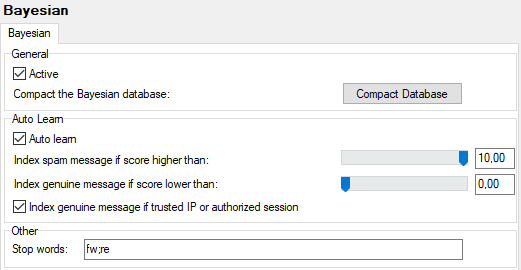
Figure. Bayesian main view.
Bayesian filters are a statistical approach to spam identification. A database of words, and their frequency of occurrence in both spam and ham messages, is built up and used to give a probability that a word contained in a message identifies it as a spam.

Figure. General section.
|
Active
|
Enables the Bayesian filters. It is recommended that this option is enabled.
|
|
Compact the Bayesian Database
|
By clicking this button, you will remove words that occur at a low frequency. These words are mostly random words that you usually see included in a spam email.
By compacting your database, the accuracy of the Bayesian filter will increase because these low frequency words have been removed.
Warning: Only the User Reference Base is compacted by this button.
|
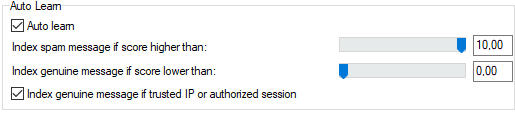
Figure. Auto learn section.
|
Auto learn
|
Check this option to enable IceWarp Server's Bayesian Auto Learn function.
Messages with spam scores in the range you specify will automatically be indexed to the User Reference Base
|
|
Index spam message if score higher than
|
Specify a value here by moving the slider. All messages assigned a score equal to or higher than this value will be indexed as spam messages.
|
|
Index genuine message if score lower than
|
Specify a value here by moving the slider. All messages assigned a spam score equal to or lower than this value will be indexed as genuine messages.
|
|
Index genuine message if trusted IP or authorized session
|
Check this option to have messages indexed as genuine if it comes from a trusted IP address or from an authorized session (i.e.: outgoing sessions that are SMTP authorized, POP before SMTP authorized, or from a trusted IP)
|

Figure. Other section.
|
Stop words
|
Contains the words to be ignored during the Spam Reference Base update (indexing process). We highly recommend that you propagate this with words that are often used in your own internal communications, such as company name, products, services, etc. Separate them using semicolons.
|

